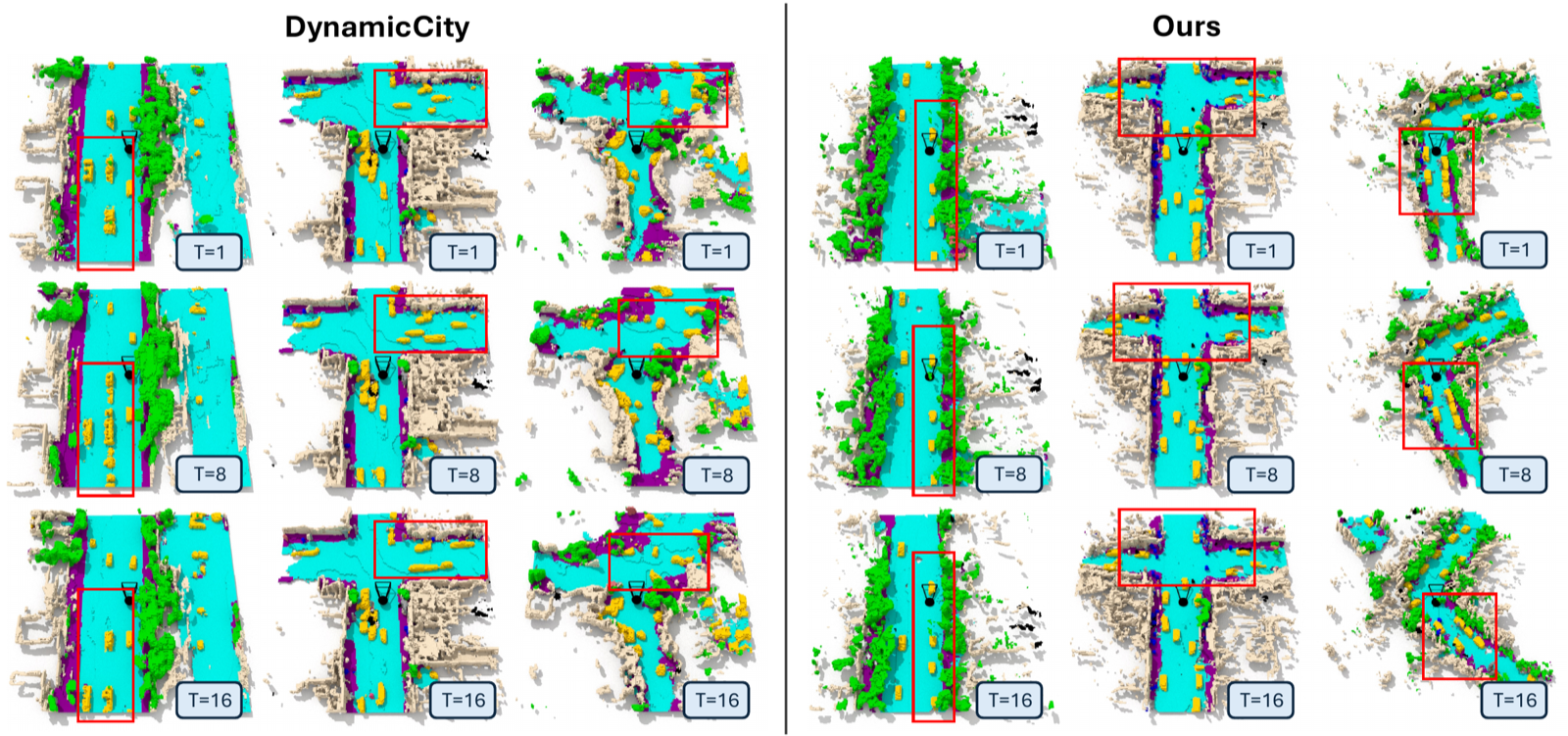
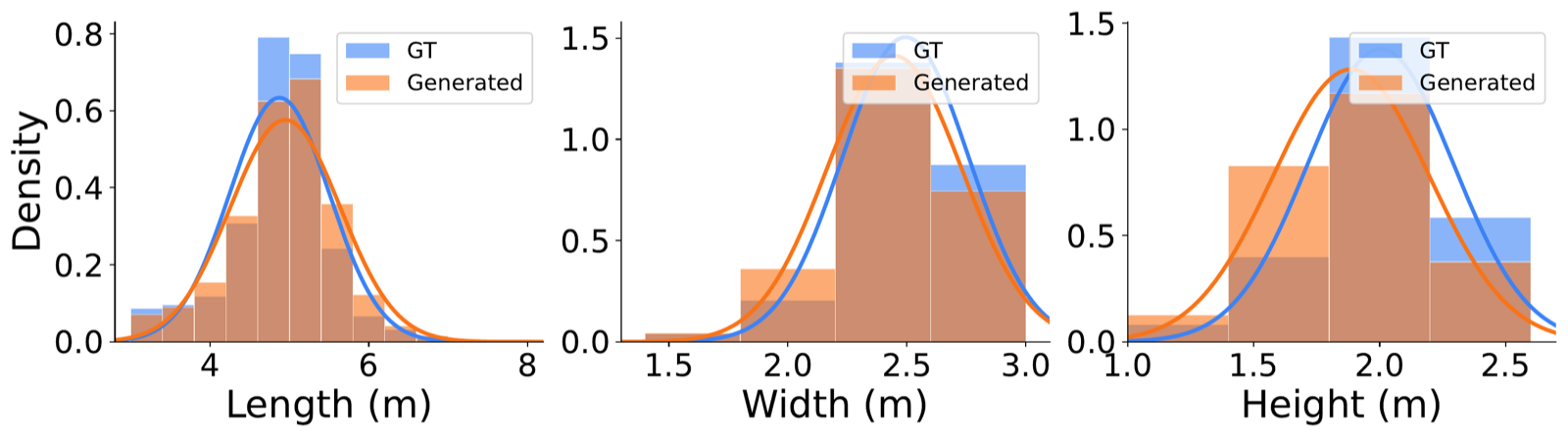
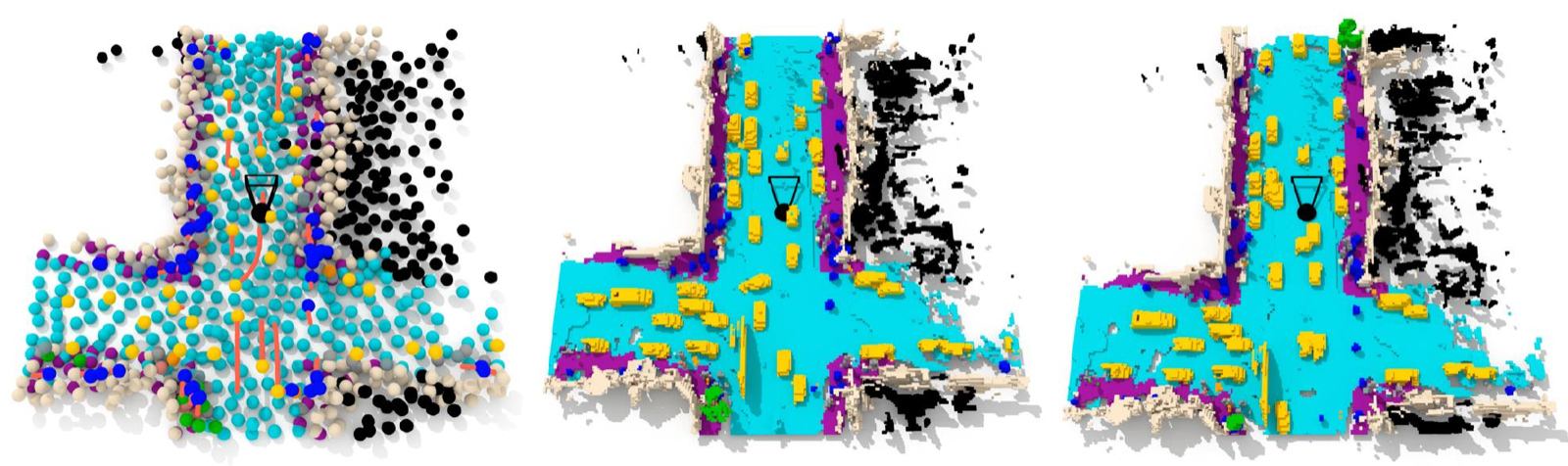
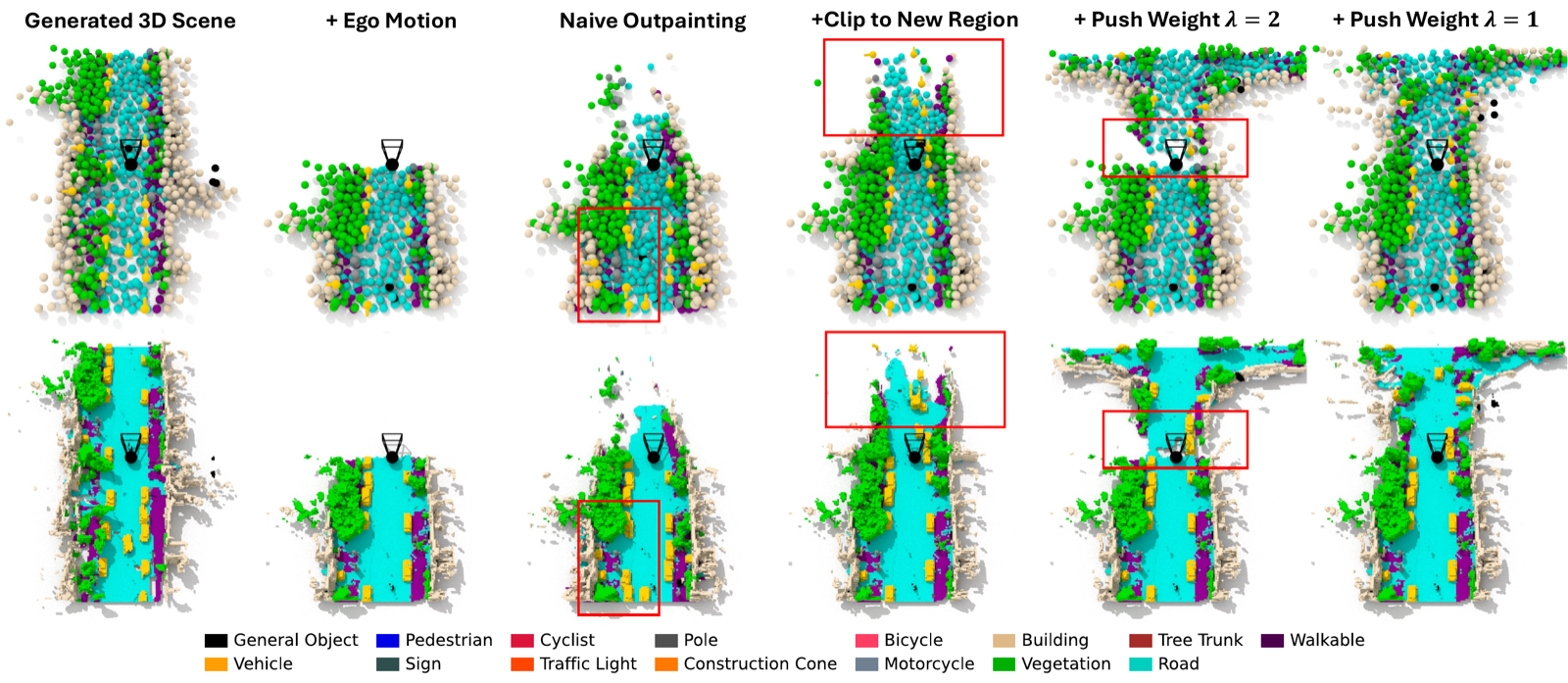
🛠️ How LatentWorld Works
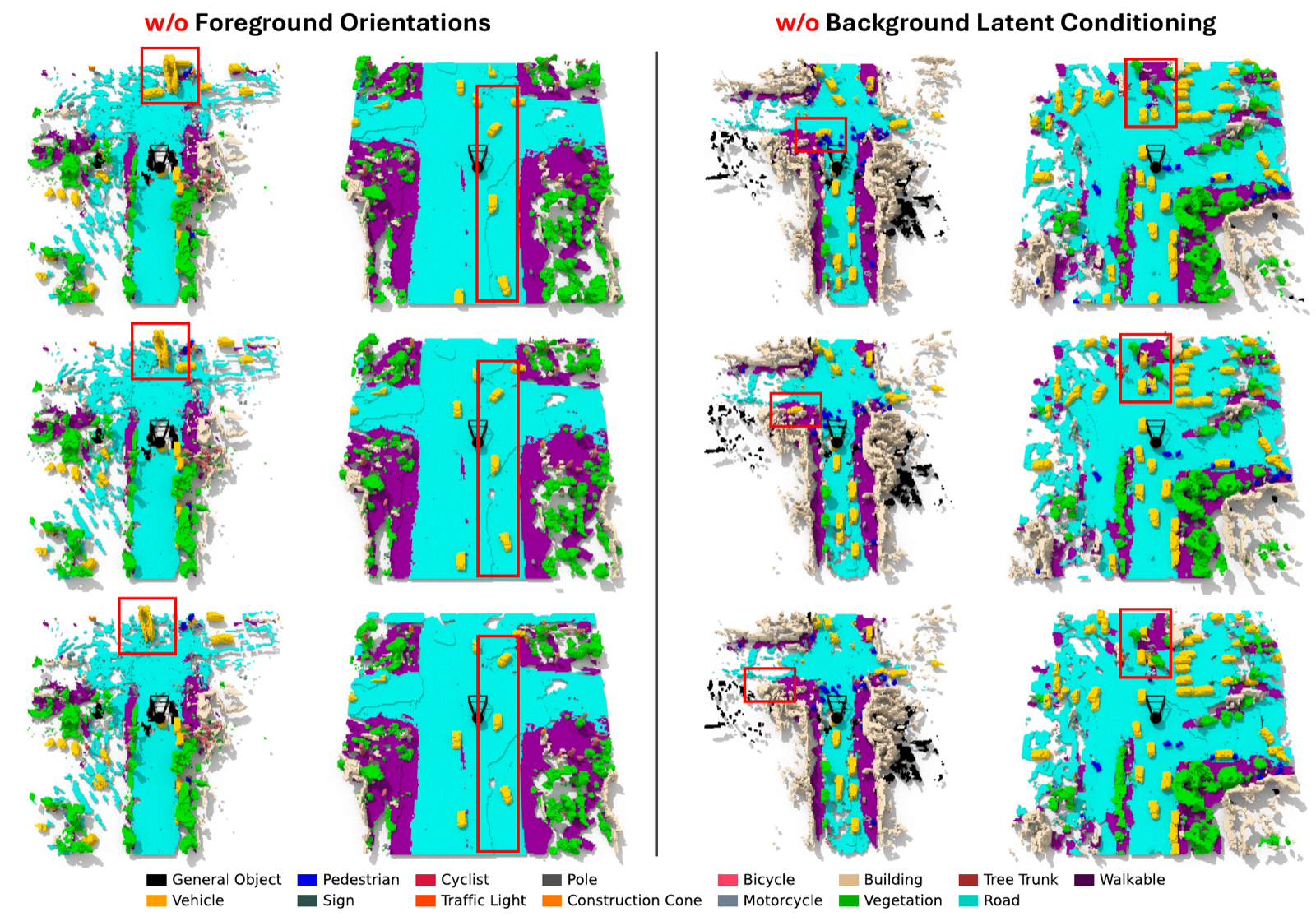
We represent a scene as a sparse set of grounded 3D latents, each a point with a position (x, y, z), a semantic class, a BEV yaw, and a feature vector. Exactly one latent is assigned to each foreground actor (vehicle, pedestrian, cyclist, and so on) to preserve identity and enable direct control, while background regions (road, buildings, vegetation) are covered by many latents for fine-grained structure. A VAE encodes semantic voxels into this latent set and decodes each latent into a small set of semantic 3D Gaussians that are splatted back to an occupancy grid.
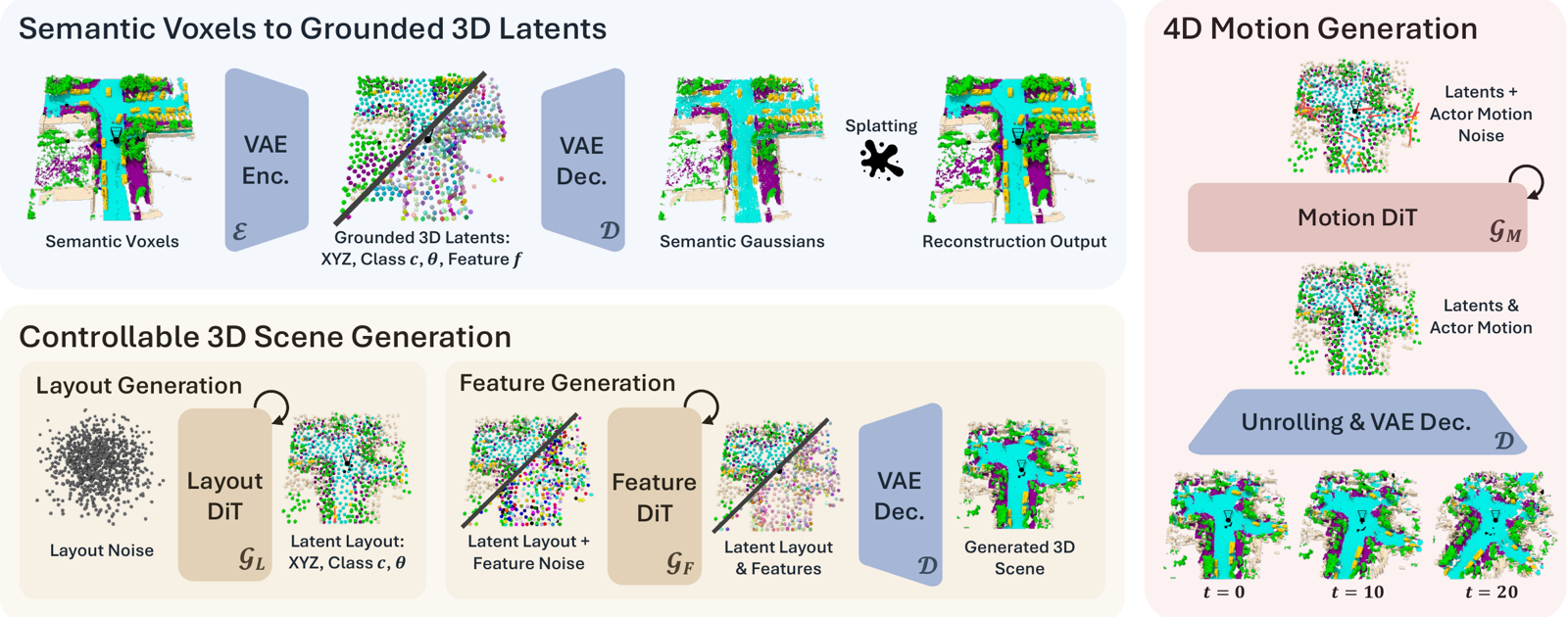
Method overview. (Semantic Voxels to Grounded 3D Latents) a VAE encodes voxels into an editable latent point set and decodes to semantic Gaussians for voxel splatting. (Controllable 3D Scene Generation) a layout diffusion transformer GL generates positions, classes, and orientations, then a feature diffusion transformer GF predicts per-latent geometry. (4D Motion Generation) a motion diffusion transformer GM produces future ego and actor trajectories; moving the latents and unrolling the decoder yields coherent 4D occupancy.
Generation is factorized into three diffusion stages over the latent set:
- Layout diffusion (GL). Generates the editable scaffold: latent positions, semantic classes (encoded as bits so discrete classes share one continuous diffusion schedule), and foreground orientations.
- Feature diffusion (GF). Conditioned on the layout, generates a per-latent feature capturing fine local geometry, so the same layout can yield diverse fine-grained geometry.
- Motion diffusion (GM). Generates future waypoints and headings for the ego vehicle and dynamic actors; ego motion is applied as a rigid transform to all latents, and unbounded rollouts are produced via an outpainting scheme.